

Nasuni was a new company to me, but they had a great presentation and I really liked what they presented. They are providing a solution to a real problem that a lot of companies are running into. The cloud is a great solution to so many problems that IT departments are encountering, but going to the cloud is not always easy as it looks. Nasuni provides a solution that simplifies the distributed NAS.
The first line from the Nasuni website says it best “Nasuni is primary and archive file storage capacity, backup, DR, global file access, and multi-site collaboration in one massively scalable hybrid cloud solution.” It does this through providing a solution to to have a “unified NAS” on top of public clouds. It is essentially and overlay that is controlled by using an on premise appliance either through a VM on your current infrastructure or a Nasuni physical appliance and keeps the data locally cached. This allows that in the event of internet access being down users can continues to access storage, and when internet is restored the data will be synced up.
There are no limits on the amount of files or file sizes. The files in a solution like this can be access by multiple users and be changing all the time. To prevent issues files are locked when a user is accessing it. Once the file is done being accessed the file will remain locked until it is synced up with the cloud. Through the continuous versioning of files and in the event of malware or such other issues. Files can be rolled back to another version before the incident occurred. All the data is deduped and compressed for effective storage utilization. Files can also be encrypted to prevent any data theft. Managing a solution like this with multiple devices across many sites could be very complex and time consuming, but with Nasuni everything is managed from a single pane limiting operation costs.
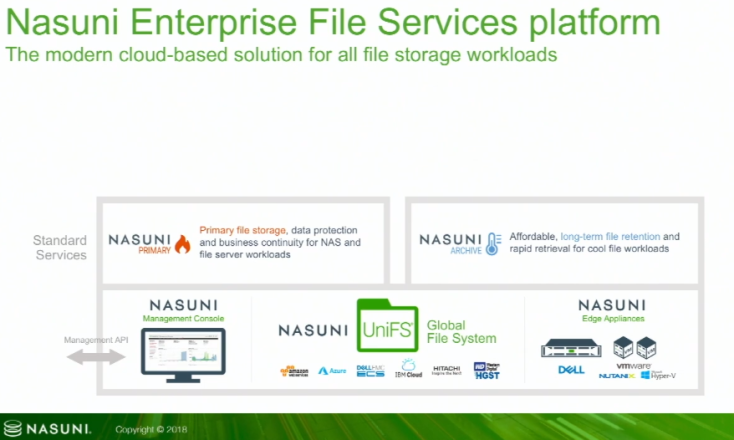
Nasuni looks like a great product that really simplifies the migration to the cloud. By supporting the big players such as AWS, Azure and GCP they give customers plenty of options on what cloud they wish to utilize. With the caching device they ensure that data can be always accessible even if there are issues preventing access to the cloud and limiting the amount of data that has to be transferred.
You can see this presentation from Nasuni and all the other presentations from Storage Field Day 16 at http://techfieldday.com/event/sfd16/




















")




Recent Comments